由于 I/O 未对齐、数据库日志记录是什么?
适用场景
ONTAP操作系统
问题解答
对于NetApp存储器的性能问题、文件管理器性能较慢的常见原因之一是部分写入。通常、Data ONTAP和WAFL可以快速完成用户写入请求、因为可以保证写入操作在写入NVRAM后会成功存储。此操作通常只需不到1 便可为NAS和SAN用户提供快速写入性能。
假设写入请求从4 k WAFL块边界开始、可被4 k整除、并且大小不小于4 k。不满足此条件的结果是部分写入、这涉及读取、将要写入的数据与读取的数据合并、然后将结果写入新块。此过程可以通过发生原因写入暂停、否则可能无法暂停、从而增加操作处理时间并增加延迟。
部分写入的一个常见原因是LUN I/O错位I/O错位的指示符是 tats perfstat_lun perfstat部分的写入对齐直方图中的LUN。
OEM注释
有关错位 I/O的详细信息、请参见知识库文章:What is an unalign齐I/O?
本文旨在讨论MS SQL (或其他数据库)日志写入导致I/O不对齐的情况、以及确定I/O是否会影响文件管理器性能的方法。
这种类型的I/O通常被视为到达多个非0分段的写入, write_partial_blocks并且也有一定的百分比:
lun:/vol/sql_log/lundggtHJeWTKaT:write_align_histo.0:0%
lun:/vol/sql_log/lundggtHJeWTKaT:write_align_histo. 1:4%
lun:/vol/sql_log/lundggtHJeWTKaT:write_align_histo.2:0%
lun:/vol/sql_log/lundggtHJeWTKaT:write_align_histo. 3:6%
lun:/vol/sql_log/lundggtHJeWTKaT:write_align_histo.4:0%
lun:/vol/sql_log/lundggtHJeWTKaT:write_align_histo. 5:57%
lun:/vol/sql_log/lundggtHJeWTKaT:write_align_histo. 6:21%
lun:/vol/sql_log/lundggtHJeWTKaT:write_align_histo.7:0%
lun:/vol/sql_log/lundggtHJeWTKaT:read_partial_blocks: 4%
lun:/vol/sql_log/lundggtHJeWTKaT: write_partial_blocks:6%
通常、如上所示的直方图会被误解为未对齐的LUN、但对LUN类型的进一步调查将显示LUN是适用于主机应用程序的正确类型。事实上、上述模式在数据库日志应用程序中很常见。在这种情况下、在讨论MS SQL Server事务日志记录时、这些主体可能也适用于其他数据库应用程序和其他工作负载。
本文用于问题解答在这种情况下经常出现的问题:
'如果LUN的类型正确且主机端已正确对齐、为什么此LUN上的I/O错位?'
在此示例中、将Windows 2008服务器视为一个服务器。NetApp LUN类型应为windows_2008。 对此LUN上创建的NTFS文件系统的I/O应自动对齐、因为起始偏移量将在默认情况下进行更正、NTFS使用系统缓冲区缓存、从而确保写入操作可被4 k整除。
那么、如果NTFS确保正确对齐写入、SQL Server如何在此NTFS分区上记录发生原因I/O错位?
问题解答是、Windows CreateFile功能提供了一个 FILE_FLAG_NO_BUFFERING 标志、用于在读取或写入文件时禁用此系统缓存。当前可用的SQL Server版本会使用此标志、并且不会始终关注对齐问题、因此写入可能会脱离对齐状态。有关此标志的详细信息,请参阅Microsoft有关 文件缓冲的文章。
虽然SQL Server事务日志记录会导致I/O错位、但不一定会对文件管理器性能产生显著影响。例如、下图涉及写入一个由一批SQL日志组成的512 K SAN块:
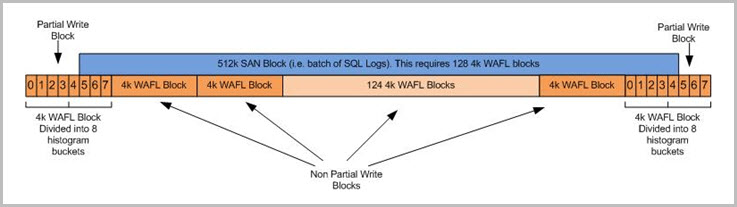
注意:A512k SAN写入占用128个4K WAFL块。如果SAN块未对齐、从WAFL块中间开始、如上述从第一个WAFL块的分段5开始的操作所示、该操作将视为未对齐、此操作将显示在 write_align_histo.5 (分段5)中。此外、用于处理此请求的第一个和最后一个WAFL块将是部分写入。但是、在这种情况下、对于这两个部分块、有126个非部分块、因此在这种情况下、影响微乎其微。
评估写入对齐直方图时、应考虑平均LUN操作大小。根据上述场景、较大的操作大小比较小的操作大小产生的影响要小。
要确定文件管理器实际受到的影响程度、请从wafl_sup –w中观察以下统计信息:
pw.over_limit是wp.partial_write计数超过时出现的次数partial_write_limit。partial_write_limit曾修复为50、但在较新版本的Data ONTAP中、此值取决于平台。WAFL_WRITE是wafl_write文件管理器在迭代期间收到的新消息的实际数量。
虽然 pw.over_limit 和 wafl_write 新消息之间的关系不是绝对的、但根据经验、影响可以通过计算 pw.over_limit 与新 WAFL_WRITE 消息的比率来确定。
例如:
pw.over_limit = 90145
WAFL_WRITE (from â??New Messagesâ?? section) = 603444
90145 / 603444\xa0= .15 or 15%
在这种情况下、每100次新WAFL写入操作中、大约15次必须同步读取块、以便合并数据来完成写入、而不是简单地将数据写入NVRAM。虽然WAFL会异步处理少量部分写入而不会阻止写入确认、但一旦WAFL未完成50个以上的部分写入、它就会开始同步处理这些操作、这会显著增加完成写入所需的时间。这些写入操作会通过 pw.over_limit 计数器反映出来。上述百分比越高、影响性能的可能性就越大。对于发生原因性能影响、百分比必须达到多高取决于任意数量的因素、因此 pw.over_limit/wafl_write ' 无法声明高水印。
追加信息
其他信息文本